Вы планируете перенести свои серверы из локального дата-центра в облако Azure? Одним из шагов на этом пути является сопоставление существующих серверов с их аналогами в Azure. Цель — снизить затраты на весь пул серверов, получив при этом максимально возможную производительность. Теоретически мы можем сопоставить исходные ВМ с целевыми, основываясь на количестве виртуальных процессоров и объёме оперативной памяти. Хотя это не самая сложная задача, она не гарантирует наилучшее соотношение производительности и цены. Если всегда выбирать самую дешёвую ВМ, можно потерять в производительности. И наоборот, максимально производительные ВМ могут оказаться слишком дорогими. Есть ли золотая середина? Давайте разбираться.
MiniZinc
Наша отправная точка — MiniZinc. Вот как он описан на их сайте:
MiniZinc — это бесплатный и открытый язык моделирования ограничений.
Вы можете использовать MiniZinc для описания задач удовлетворения ограничений и оптимизации на высоком уровне, независимо от решателя, используя обширную библиотеку предопределённых ограничений. Ваша модель затем компилируется в FlatZinc — язык, понятный широкому кругу решателей.
MiniZinc разрабатывается в Университете Монаша в сотрудничестве с Data61 Decision Sciences и Мельбурнским университетом.
Проще говоря, MiniZinc — это особый декларативный язык программирования для описания и решения задач определённого класса. Он также служит абстрактным уровнем над набором решателей (solvers), позволяя написать код один раз и попробовать решить задачу с помощью разных решателей (solvers).
В нашем случае мы решаем задачу оптимизации с ограничениями, используя MiniZinc.
Что мы собираемся сделать
В этом разделе мы проведём небольшой эксперимент, проанализируем результат и объясним его. Следующий раздел содержит высокоуровневое описание, как всё это работает. Обратите внимание, что для запуска всего этого на Windows-системе, возможно, потребуется скачать и установить MiniZinc. Также убедитесь, что minizinc.exe находится в переменной окружения PATH.
Вспомогательный скрипт находится здесь. Он подготавливает окружение для эксперимента.
Начнём с упрощённого варианта. Наше решение состоит из трёх основных компонентов:
- Модель MiniZinc
- Входные данные для модели
- Несколько скриптов для удобства
Входные данные включают:
- Информацию об исходных серверах: их CPU, RAM и диск
- Информацию о виртуальных машинах Azure в регионе eastus2
- Информацию о дисках Azure
Модель пытается сопоставить каждый исходный сервер с облачным аналогом, при этом соблюдая заданные ограничения. Например, модель требует, чтобы объём RAM в облаке был не меньше, чем у исходной машины.
В лучшем случае решатель гарантирует, что решение оптимально.
Для запуска импортируем вспомогательные функции:
. .\vm-optimization-minizinc\helperFunctions.ps1
Мы запустим три разных теста:
- Простой тест: оптимизация стоимости и производительности по отдельности
cost -> performance: сначала минимизируем стоимость, затем пытаемся улучшить производительность, не выходя за пределы бюджетаperformance -> cost: сначала максимизируем производительность, затем пробуем снизить стоимость без её ухудшения
Простой тест — оптимизация по отдельности
Минимизация стоимости:
Start-MinizincVMOptimizationModel -Costs
totalPrice totalACU vmRecords
---------- -------- ---------
42.4778 9200 {@{sourceVMName=vmN1; sourceVMCPU=2; sourceVMRAM=12; sourceVMDisk=460; selecte…
Максимизация производительности:
Start-MinizincVMOptimizationModel -Performance
totalPrice totalACU vmRecords
---------- -------- ---------
146.496 18860 {@{sourceVMName=vmN1; sourceVMCPU=2; sourceVMRAM=12; sourceVMDisk=460; selecte…
Как видно, первый вариант значительно дешевле. Но чтобы удвоить производительность, приходится потратить более чем в 3 раза больше. Можно ли сделать лучше?
Минимизация стоимости при сохранении производительности
Мы используем Azure Compute Unit (ACU) как показатель производительности. Мы получаем его из Azure API и стараемся максимизировать.
В этом тесте сначала минимизируем стоимость, затем оптимизируем производительность:
$ret = Start-MinizincVMOptimizationModel -Costs | Start-MinizincVMOptimizationModel -Performance
$ret
totalPrice totalACU vmRecords
---------- -------- ---------
42.4778 9410 {@{sourceVMName=vmN1; sourceVMCPU=2; sourceVMRAM=12; sourceVMDisk=460; selecte…
Стоимость осталась минимальной, но производительность выросла.
Посмотрим, какие размеры ВМ были выбраны:
$csv = ($ret.vmRecords | ConvertTo-Csv -NoTypeInformation) -join "`n"
$df = [Microsoft.Data.Analysis.DataFrame]::LoadCsvFromString($csv)
[Microsoft.DotNet.Interactive.Kernel]::display($df)
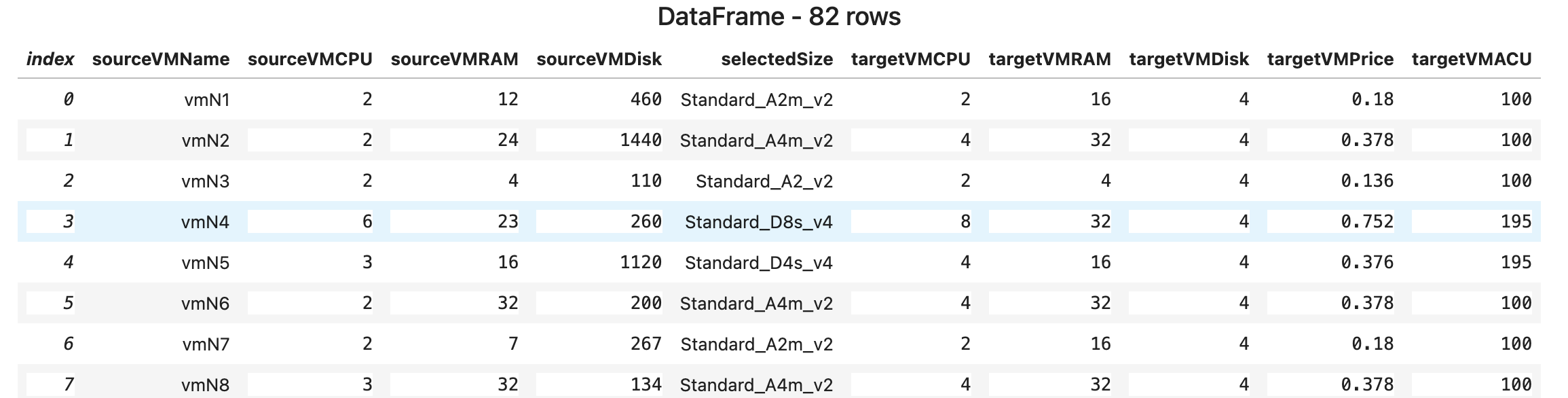
Колонка targetVMACU всегда равна 100. Это и дало прирост.
Можно также использовать HTML-таблицу:
$view = $ret.vmRecords | ConvertTo-Html -Fragment
[Microsoft.DotNet.Interactive.Kernel]::HTML($view) | Out-Display
Минимизация стоимости без потери производительности
Теперь попробуем наоборот — сначала максимизируем производительность, потом минимизируем стоимость:
$ret2 = Start-MinizincVMOptimizationModel -Performance | Start-MinizincVMOptimizationModel -Costs
$ret2
totalPrice totalACU vmRecords
---------- -------- ---------
54.936 18860 {@{sourceVMName=vmN1; sourceVMCPU=2; sourceVMRAM=12; sourceVMDisk=460; selecte…
Цена чуть выше минимальной, но производительность максимальна — это победа!
$csv = ($ret2.vmRecords | ConvertTo-Csv -NoTypeInformation) -join "`n"
$df2 = [Microsoft.Data.Analysis.DataFrame]::LoadCsvFromString($csv)
[Microsoft.DotNet.Interactive.Kernel]::display($df2)
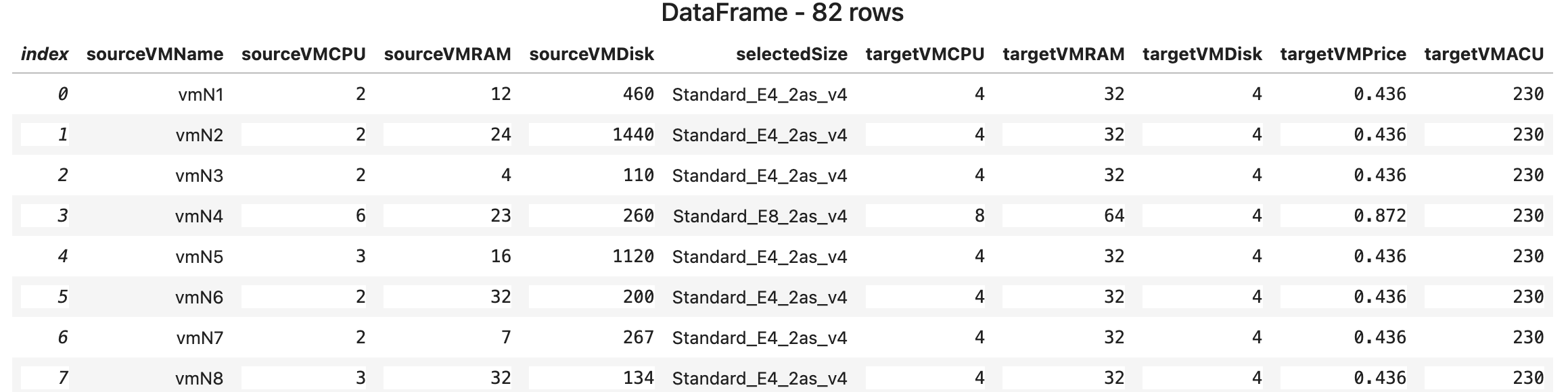
Модель выбрала другие размеры ВМ — это и помогло.
Как это работает
Тем, кто хочет заглянуть под капот — ниже диаграмма:
Главное — это модель. Мы описываем, что хотим найти, а решатель делает всё остальное.
Пример ограничения по RAM:
constraint forall(vm in existingVMs)(
vmSizeRAM[selectedSize[vm]] >= vmRAM[vm]
);
А по CPU — допускаем 20% меньше:
constraint forall(vm in existingVMs)(
vmSizeCPU[selectedSize[vm]] >= vmCPU[vm] * 0.8
);
Целевые функции:
var int: totalPrice = sum(vm in existingVMs)(vmSizePrice[selectedSize[vm]]);
var int: totalACU = sum(vm in existingVMs)( vmSizeACU[selectedSize[vm]] );
Решаемые переменные:
array[existingVMs] of var vmSizes: selectedSize;
Ключевое слово solve определяет, что оптимизировать:
solve satisfy— просто удовлетворить ограниченияsolve minimize ...— минимизироватьsolve maximize ...— максимизировать
Мы запускаем модель дважды, передавая результат через пайплайн PowerShell.
Пример:
Start-MinizincVMOptimizationModel -Costs | Start-MinizincVMOptimizationModel -Performance
Так мы поочерёдно оптимизируем две функции.