(Или как мы перестали волноваться и полюбили облако)
Задумывались ли вы когда-нибудь, как облачный многoагентный AI-сервис справляется с потоком входящих запросов пользователей и при этом не взрывается? Что ж, больше не нужно гадать! В этой статье мы отправимся в лёгкое и весёлое путешествие по симуляции, которая проверяет, насколько устойчиво масштабируется и справляется с трафиком система агентного AI (представьте: множество AI-агентов, работающих вместе). Мы расскажем про наш фреймворк, предположения, код и результаты — включая симпатичный график, чтобы продемонстрировать собранные данные.
Задача
Представьте, что вы управляете волшебной системой многoагентного AI в облаке. Пользователи постоянно шлют запросы, каждый из которых содержит определённое количество токенов, и вашим AI-агентам нужно понять, как с ними справиться. Иногда запросы разбиваются на части, если требуют особой обработки, иногда они отбрасываются, если их слишком много. Мы хотим выяснить:
- Сколько всего запросов мы получаем?
- Как часто мы отбрасываем запросы, учитывая ограниченные ресурсы кластера?
- Как это влияет на потребление ресурсов и общую стоимость (в долларах)?
Другими словами, мы хотим смоделировать повседневную жизнь агентной AI-системы и увидеть, что происходит при нагрузке.
Наш симуляционный фреймворк
Для симуляции мы надели свои Python-шляпы и создали игровую среду. Мы использовали SimPy — фреймворк дискретной событийной симуляции на основе стандартного Python. Основные шаги выглядели так:
- Генерация входящих запросов: создаём поток пользовательских запросов со случайным числом токенов.
- Маршрутизация запросов: некоторые обрабатываются напрямую агентом, другие разбиваются на подагентов — имитируя сложные запросы.
- Моделирование затрат: считаем количество токенов, используемых каждым запросом, затем рассчитываем стоимость использования LLM и AKS (Azure Kubernetes Service) на основе потребления — в долларах.
- Статистика: фиксируем всё — число прямых, разбитых и отброшенных запросов, общее число токенов и стоимость.
- Повтор: запускаем симуляцию множество раз (в нашем случае — 100), чтобы получить усреднённые значения.
Этот фреймворк позволяет увидеть, как гипотетическая AI-система в облаке будет вести себя в разных условиях.
Предположения и параметры
Теперь к интересному — какие числа мы заложили?
- Распределение токенов: мы предположили, что запросы пользователей бывают разного размера, с определённым средним и стандартным отклонением. Система (т.е. набор агентов) может добавлять накладные токены к каждому запросу — ну, потому что «система же работает».
- Порог разделения: считаем, что определённая доля запросов слишком сложная и требует разбивки. Поток делится случайным образом, согласно этой доле.
- Стоимость в долларах: мы использовали условную модель — например, миллион токенов стоит определённую сумму, каждый AKS-узел — сколько-то в час. Мы держали всё в разумных пределах для демонстрации.
- Отбрасывание запросов: если запрос слишком большой или кластер перегружен, мы позволяем системе его отбросить. Мол, дешевле проигнорировать, чем масштабировать до бесконечности — жёстко, но это всего лишь симуляция!
Наша цель — не абсолютный реализм, а демонстрация компромиссов и поведения системы в разных условиях.
Быстрый взгляд на код
Мы не будем грузить вас деталями, но общий вид кода таков:
import numpy as np
import pandas as pd
from tqdm import trange
NUM_RUNS = 100
results = []
for run in trange(NUM_RUNS):
# 1. Generate requests
user_queries = np.random.poisson(lam=5000, size=some_size) # Just an example
# 2. Route requests
direct_requests = 0
split_requests = 0
dropped_requests = 0
total_tokens = 0
# ... Some logic for splitting or dropping requests ...
# 3. Track costs (in dollars)
llm_cost = ...
aks_cost = ...
total_cost = llm_cost + aks_cost
# 4. Append results for each run
results.append({
'direct_requests': direct_requests,
'split_requests': split_requests,
'dropped_requests': dropped_requests,
'total_requests': direct_requests + split_requests,
'llm_cost': llm_cost,
'aks_cost': aks_cost,
'total_cost': total_cost,
# ... other stats ...
})
# Convert results to a DataFrame and compute summary statistics
df = pd.DataFrame(results)
summary = df.describe()
print(summary)
Вкратце:
- Генерируются запросы со случайным числом токенов.
- Определяется: обрабатываем напрямую, разбиваем или отбрасываем.
- Считается количество токенов и стоимость.
- Все метрики собираются в DataFrame, и выводится сводная статистика.
Вы можете найти ноутбук здесь
Результаты
После 100 прогонов мы получили следующие данные:
| Metric | mean | std | min | max |
|---|---|---|---|---|
| direct_requests | 6479 | 85.76 | 6279 | 6641 |
| split_requests | 25931 | 157 | 25462 | 26347 |
| dropped_requests | 591 | 38.74 | 506 | 696 |
| total_requests | 32410 | 182 | 31945 | 32823 |
| percent_split | 80.01 | 0.23 | 79.46 | 80.60 |
| user_query_tokens | 3561909 | 53503 | 3445529 | 3669273 |
| system_query_tokens | 95085770 | 517611 | 93430542 | 96296984 |
| llm_response_tokens | 42782889 | 225980 | 42077728 | 43267966 |
| total_llm_tokens | 141430570 | 743063 | 139073264 | 143077558 |
| llm_cost (USD) | 424 | 2.23 | 417 | 429 |
| aks_cost (USD) | 858 | 2.32 | 852 | 864 |
| total_cost (USD) | 1283 | 4.35 | 1269 | 1293 |
| max_nodes | 11.00 | 0.00 | 11.00 | 11.00 |
| avg_nodes | 8.01 | 0.02 | 7.95 | 8.07 |
Что это всё значит?
- Мы отбрасываем относительно немного запросов (в среднем 591), что говорит о том, что кластер справляется и способен выдерживать нагрузку.
- Общая стоимость около $1283, из которых $424 — это LLM, а $858 — AKS. Похоже, AI-доступ обходится дешевле, чем инфраструктура.
- Максимум — 11 узлов, среднее — около 8. Значит, запас по масштабированию есть, и мы не сразу начнём терять запросы.
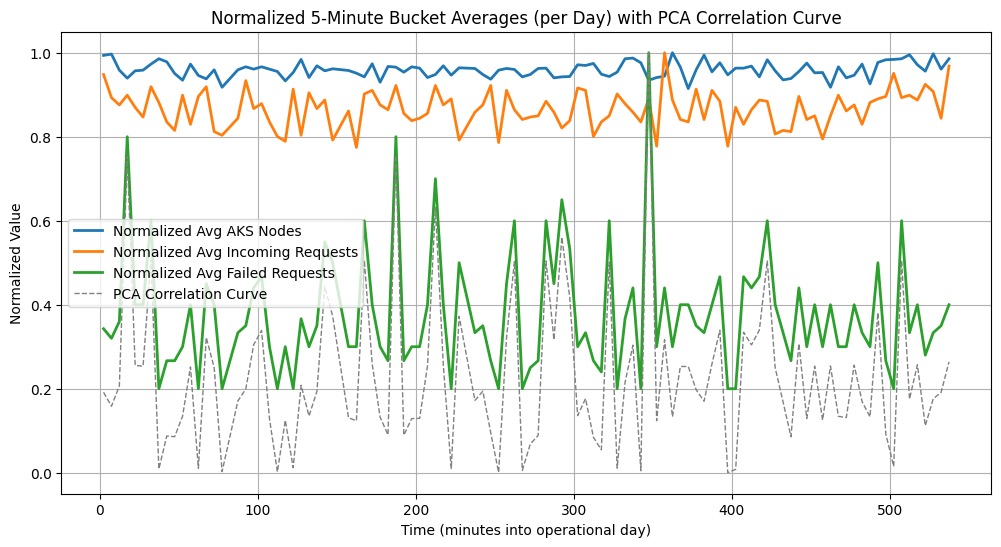
На графике (см. ниже) видно:
- Нормализованное среднее по узлам AKS: использование ресурсов во времени.
- Нормализованные входящие запросы: нагрузка на систему.
- Нормализованные неудачные запросы: когда система отбрасывает запросы.
- PCA кривая корреляции: показывает, какие метрики взаимосвязаны. Если пики высокие — значит, между метриками сильная связь.
Заключение (и вопрос к вам!)
Вот и всё! Эта симуляция показывает, как может вести себя облачная агентная AI-система при разной нагрузке, размере токенов и ограничениях по стоимости. В реальности вы бы адаптировали параметры под свои условия.
Вопрос: если у вас есть подобная система — как ваши показатели соотносятся с нашими? Может, у вас другой процент разбивки или иная стоимость? Поделитесь опытом!
Надеемся, вам было интересно заглянуть в мир симуляций и планирования ресурсов. Если вы когда-нибудь задавались вопросом, «а не взорвётся ли мой кластер?», — быстрая симуляция может дать уверенность или хотя бы направление для исследований.
Спасибо, что были с нами в этом путешествии по облакам, токенам и AI-агентам. До новых встреч — и удачных симуляций!